Top-Down Saliency
In Kanan et al. (2009) we developed the SUN model of top-down visual saliency. As of early 2009, it is one of the best models for predicting what people will look at in natural images. However, the model knows nothing about human eye movements. SUN’s predictive power is based on its ability to find the areas in a picture that are most likely to be the object it is searching for, just as people do. For the full details of the model’s implementation and evaluation please refer to our paper.
To develop SUN we used the LabelMe dataset to train a classifier using features inspired by the properties of neurons in primary visual cortex. Torralba et al. (2006) gathered eye movement data from people who were told to look for particular objects (mugs, paintings, and pedestrians) in natural images. We used their data to evaluate how well SUN predicts the subject’s eye movements when it is given the very same images, which SUN has never seen before. We compared our model to Torralba et al.’s Contextual Guidance Model, which is one of the few models with a comparable ability to predict human eye movements in natural images.
Results
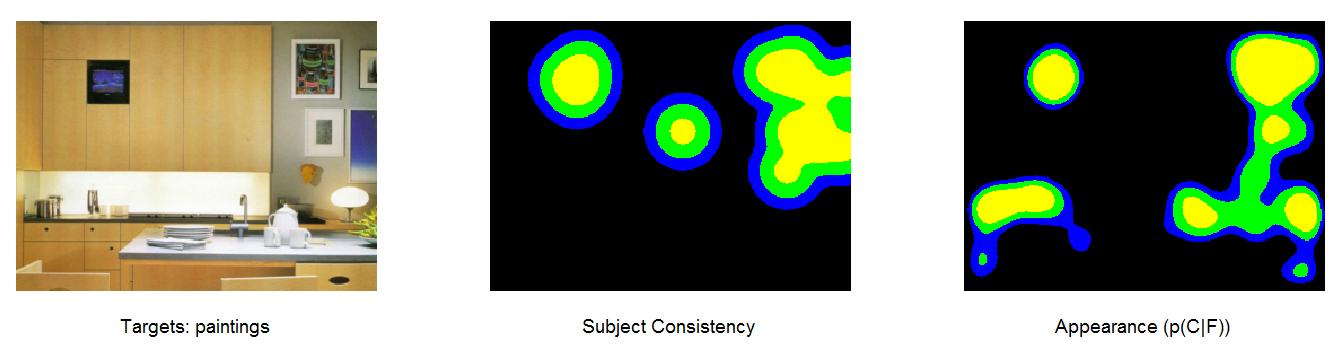
The subjects were told to find the paintings when they were shown the above left picture. As you can see from the above middle picture, the people did look at the paintings. However, they also looked looked at the television embedded in the cabinet, which is the same thing SUN does as shown in the above right picture. It has been argued that humans don’t look for an object’s features until after a few fixations (Torralba et al., 2006), since typically the object locations are not very predictive of where people will look. However, this is at least somewhat due to objects like televisions looking like the target.
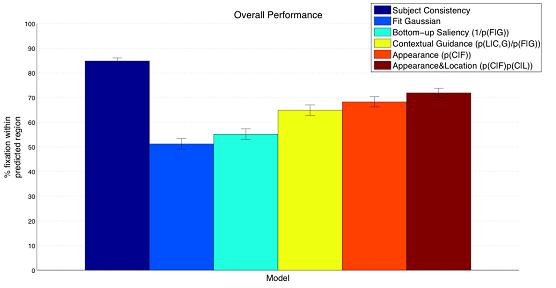
The figure above shows the predictive accuracy of several models. The best model (dark blue) is to use the eye movements of all of the people, except the one being tested, to predict the tested person’s eye movements. This serves as an upper bound on how well any model could probably hope to perform. A stimulus driven (bottom-up saliency) model doesn’t work very well. Taking the task into account dramatically improves performance as both the Contextual Guidance Model (yellow) and SUN (orange and red) are able to predict human eye movements with good accuracy. However, these models are not even close to the model that was fit to the human eye movement data for each image (dark blue).
There is a lot of work left to do, but our models are gradually getting better.
References
Kanan, C., Tong, M. H., Zhang, L., & Cottrell, G. W. (2009). SUN: Top-down saliency using natural statistics. Visual Cognition, 17: 979-1003.
Torralba, A., Oliva, A., Castelhano, M. S., & Henderson, J. M. (2006). Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search. Psychological Review, 113: 766-786.