Mind Builder

In early 2008, a group of researchers at the University of Michigan presented evidence a dual N-Back game that used both spatial and audible features could be used to enhance working memory and fluid intelligence (see Jaeggi et al, 2008). As the players achieved higher levels of difficulty in the game their score on an intelligence assessment test increased. The players each trained for around 25 minutes a day, and the more days they trained the more their fluid intelligence improved. Fluid intelligence is closely related to the ability to learn new cognitive tasks. Prior to their result, most scientists argued that fluid intelligence could not increase with training.
A few days after this paper was published, I developed Mind Builder, a web game based based on the game in their paper. I made a variety of enhancements to their original concept to make the game more fun and to increase the difficulty more gradually. There is also a version of Mind Builder for iPhone, iPod Touch, and iPad. You can get the iOS version here.
You can find a web-based version of the game that has been modified to be more fun here.
You can find the “traditional” version of the game here, but the difficulty increases much faster.
The web-based version unfortunately doesn’t work in all browsers and it requires Flash (for sounds), so if it doesn’t work try switching web browsers. Feel free to email me with comments, suggestions, and bug reports.
The Dual N-Back Task
The dual N-Back game as described in the paper by Jaeggi et al. (2008) subjects a player to both visual and audible information that the player must remember in order to advance to the next level of difficulty. This is best illustrated with a picture.
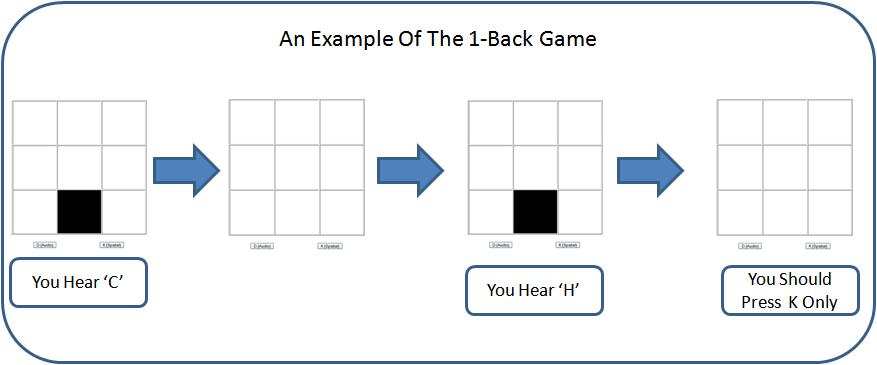
For the 1-Back game, the player presses the K key if the same square “lights” up in the current presentation and in the last presentation. The player also presses the D key if the same sound occurs during the current presentation and the previous one. In a given round the player might do nothing, press the K key, press the D key, or press both.
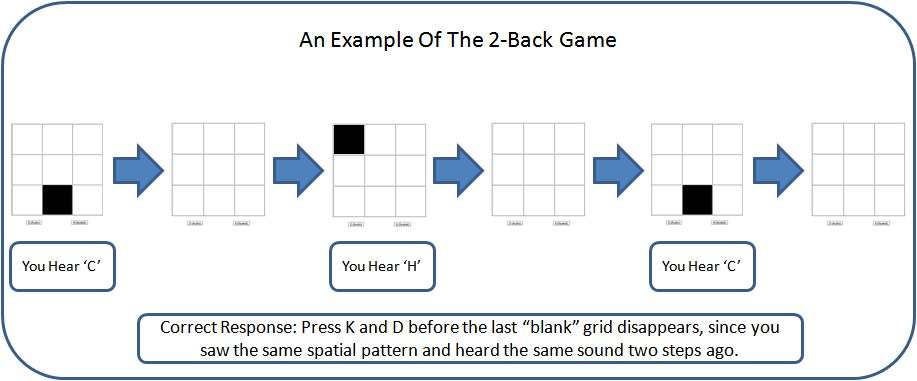
If the player does well, then N is increased. If the player does poorly, then N is decreased. The dual 2-Back game feels significantly harder than the dual 1-Back game. As illustrated in the diagram above, the player’s response in the current round is based on what the player saw two rounds ago. The game continues to increase in difficulty indefinitely. In their study, some players were able to reach at least N = 6 after playing the game for around 25 minutes a day for 19 days. They showed the greatest improvement in fluid intelligence.
You can find my implementation of what I call the “traditional” dual N-Back task here. It does contain some small changes though. For example, instead of players being shown only 6 correct matches in a game, my version shows at least 6. It also does not have the big target in the center square. However, see below for information about a modified version that I made to make the game more interesting.
My Modifications
After I implemented the task almost exactly as described in the Jaeggi et al. paper, I found that while the dual 1-Back task was very easy for the handful of play testers I found, the dual 2-Back task was much harder. So, I decided to try to increase the difficulty more gradually. I added in a third feature, color, to keep track of that is invariant with respect to the sounds and position. However, only some of these features are present in each level. Between levels, the grid size, whether audio cues are used, whether color cues are used, as well as N are changed to make the game more interesting. I also removed the decrease in difficulty that occurs if the user does poorly, since players reported it discouraged them from playing. If they mastered the 1-Back task, but had difficulty with the 2-Back task, they didn’t want to replay what they had mastered. When the user responds they now receive feedback about whether they were right or wrong. Also, some location levels use pictures of baby animals.
For More Information
Wired Article on Fluid Intelligence
Science Daily Article on Fluid Intelligence
New York Times Article on Fluid Intelligence
PNAS Paper by Jaeggi, Buschkuehl, Jonides, and Perrig